Hi, yeah of course, I apologize.
import pandas as pd
import random
import datetime
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from concrete.ml.sklearn import LogisticRegression
import numpy
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import RobustScaler
from concrete.ml.sklearn import LogisticRegression as ConcreteLogisticRegression
Define a list of first names, last names, jobs, and social classes
first_names = [‘John’, ‘Mary’, ‘Robert’, ‘Patricia’, ‘David’, ‘Jennifer’, ‘Michael’, ‘Linda’, ‘William’, ‘Elizabeth’]
last_names = [‘Smith’, ‘Johnson’, ‘Brown’, ‘Taylor’, ‘Miller’, ‘Wilson’, ‘Moore’, ‘Anderson’, ‘Jackson’, ‘White’]
jobs = [‘Doctor’, ‘Lawyer’, ‘Teacher’, ‘Engineer’, ‘Accountant’, ‘Programmer’, ‘Salesperson’, ‘Chef’, ‘Nurse’, ‘Builder’]
social_classes = [‘Upper’, ‘Middle’, ‘Lower’]
Define a function to generate a random salary based on the job
def get_salary(job):
if job == ‘Doctor’:
return random.randint(120000, 500000)
elif job == ‘Lawyer’:
return random.randint(100000, 400000)
elif job == ‘Teacher’:
return random.randint(40000, 80000)
elif job == ‘Engineer’:
return random.randint(70000, 150000)
elif job == ‘Accountant’:
return random.randint(50000, 120000)
elif job == ‘Programmer’:
return random.randint(60000, 130000)
elif job == ‘Salesperson’:
return random.randint(30000, 90000)
elif job == ‘Chef’:
return random.randint(25000, 60000)
elif job == ‘Nurse’:
return random.randint(40000, 80000)
elif job == ‘Builder’:
return random.randint(20000, 50000)
Define a function to get the social class based on the salary
def get_social_class(salary):
if salary >= 100000:
return ‘Upper’
elif salary >= 50000:
return ‘Middle’
else:
return ‘Lower’
Define a function to generate a random number of children based on the family status
def get_num_children(family_status):
if family_status == ‘Married with Kids’:
return random.randint(1, 3)
elif family_status == ‘Married without Kids’:
return 0
elif family_status == ‘Single with Kids’:
return random.randint(1, 2)
else:
return 0
Define the number of users
num_users = 100
Create an empty DataFrame
users_df = pd.DataFrame(columns=[‘First Name’, ‘Last Name’, ‘Age’, ‘Job’, ‘Salary’, ‘Hours Per Week’, ‘Family Status’,
‘Social Class’, ‘Number of Children’, ‘Last 10 Search Queries’, ‘Days Since Last Search’,
‘Days Till July 1st’, ‘Visited Location’])
Iterate over the number of users and create random data for each user
for i in range(num_users):
# Generate a random first name, last name, age, job, and family status
first_name = random.choice(first_names)
last_name = random.choice(last_names)
age = random.randint(20, 65)
job = random.choice(jobs)
family_status = random.choice([‘Married with Kids’, ‘Married without Kids’, ‘Single with Kids’, ‘Single without Kids’])
# Generate a random salary based on the job
salary = get_salary(job)
# Generate a random number of hours worked per week
hours_per_week = random.randint(20, 60)
# Get the social class based on the salary
social_class = get_social_class(salary)
# Get the number of children based on the family status
num_children = get_num_children(family_status)
# Generate random search queries
search_queries = ['Tokyo', 'Delhi', 'Shanghai', 'Sao Paulo', 'Mumbai', 'Mexico City', 'Beijing', 'Osaka', 'Cairo', 'New York', 'Dhaka', 'Karachi', 'Buenos Aires', 'Istanbul', 'Kolkata', 'Manila', 'Lagos', 'Rio de Janeiro', 'Tianjin', 'Kinshasa', 'Guangzhou', 'Los Angeles', 'Moscow', 'Shenzhen', 'Lahore', 'Bangalore', 'Paris', 'Bogota', 'Jakarta', 'Chennai', 'Lima', 'Bangkok', 'Hyderabad', 'London', 'Nagoya', 'Chengdu', 'Tehran', 'Chicago', 'Chongqing', 'Nanjing', 'Wuhan', 'Ho Chi Minh City', 'Luanda', 'Ahmedabad', 'Kuala Lumpur', 'Surat', 'Baghdad', 'Johannesburg', 'Riyadh', 'Madrid', 'Pune', 'Houston', 'Singapore', 'Toronto', 'Saint Petersburg', 'Kanpur', 'Yangon', 'Chittagong', 'Changchun', 'Lanzhou', 'Belo Horizonte', 'Bangui', 'Phoenix', 'Xi`an', 'Porto Alegre', 'Suzhou', 'Santiago', 'Qingdao', 'Shenyang', 'Dalian', 'Kiev', 'Lucknow', 'Jinan', 'Zhengzhou', 'Taipei', 'Kunming', 'Khartoum', 'Guayaquil', 'Jeddah', 'Nairobi', 'San Francisco', 'Zibo', 'Denver', 'San Diego', 'San Antonio', 'Dubai', 'Recife', 'Seattle', 'Harbin', 'Tampa', 'Sapporo', 'Brasilia', 'Durban', 'Izmir', 'Kyoto', 'Jaipur', 'Nashville', 'Addis Ababa', 'Daegu', 'Baltimore', 'Adana', 'Kwangju', 'Fukuoka', 'Munich', 'Hamburg', 'Rosario', 'Ibadan', 'Mashhad', 'Medellin', 'Baku', 'Orlando', 'Gaziantep', 'Warsaw', 'Vancouver', 'Incheon', 'Cleveland', 'Taiyuan', 'Vienna', 'Cincinnati', 'Beirut', 'Nuremberg', 'Nanning', 'Bhopal', 'Manaus', 'Bursa', 'Thessaloniki', 'Johor Bahru', 'Montreal', 'Rostov-on-Don', 'Sofia', 'Goiania', 'Columbus', 'Recife', 'Lviv', 'Krasnoyarsk', 'Hefei', 'Nizhny Novgorod', 'Marseille', 'Athens', 'Kazan', 'Zaozhuang', 'Chelyabinsk', 'Naples', 'Shangrao', 'Gujranwala', 'Naha', 'Las Vegas', 'Bilbao', 'Saratov', 'Cordoba', 'Rosario', 'Antalya', 'Diyarbakir', 'Zhangjiakou', 'Perm', 'Varanasi', 'Homs', 'Pingxiang', 'Rabat', 'Krasnodar']
# Generate random days since last search
days_since_last_search = random.randint(0, 30)
# Generate random days till July 1st
days_till_july_1st = (datetime.date(datetime.datetime.now().year, 7, 1) - datetime.datetime.now().date()).days
list_1=[]
for i in range(10):
a=random.choice(search_queries)
list_1.append(a)
# Generate random European location visit
visited_location = random.choice(list_1)
# Add the data for this user to the DataFrame
users_df = users_df.append({
'First Name': first_name,
'Last Name': last_name,
'Age': age,
'Job': job,
'Salary': salary,
'Hours Per Week': hours_per_week,
'Family Status': family_status,
'Social Class': social_class,
'Number of Children': num_children,
'Last 10 Search Queries': list_1,
'Days Since Last Search': days_since_last_search,
'Days Till July 1st': days_till_july_1st,
'Visited Location': visited_location
}, ignore_index=True)
users_df.head()
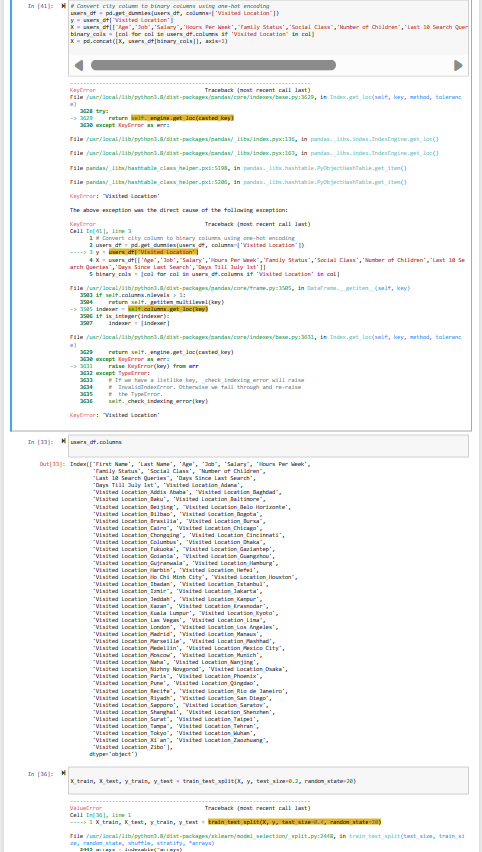
Convert city column to binary columns using one-hot encoding
users_df = pd.get_dummies(users_df, columns=[‘Visited Location’])
y = users_df[‘Visited Location’]
X = users_df[[‘Age’,‘Job’,‘Salary’,‘Hours Per Week’,‘Family Status’,‘Social Class’,‘Number of Children’,‘Last 10 Search Queries’,‘Days Since Last Search’,‘Days Till July 1st’]]
binary_cols = [col for col in users_df.columns if ‘Visited Location’ in col]
X = pd.concat([X, users_df[binary_cols]], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=20)
Scale the features
scaler = RobustScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Fit a logistic regression model
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
Evaluate the model on the test set
y_pred_test = np.asarray(logreg.predict(X_test))
sklearn_acc = np.sum(y_pred_test == y_test) / len(y_test) * 100
Quantize and evaluate the model on the test set
q_logreg = ConcreteLogisticRegression(n_bits={“inputs”: 5, “weights”: 2})
q_logreg.fit(X_train, y_train)
q_logreg.compile(X_train)
q_y_pred_test = q_logreg.predict(X_test)
quantized_accuracy = (q_y_pred_test == y_test).mean() * 100
q_y_pred_fhe = q_logreg.predict(X_test, execute_in_fhe=True)
homomorphic_accuracy = (q_y_pred_fhe == y_test).mean() * 100
print(f"Regular Sklearn model accuracy: {sklearn_acc:.4f}%“)
print(f"Clear quantised model accuracy: {quantized_accuracy:.4f}%”)
print(f"Homomorphic model accuracy: {homomorphic_accuracy:.4f}%")