First of all some background informations:
I want to achieve an anomaly detector. Since it’s not possible yet to use IsolationForest in ConcreteML I have the following pipeline:
- Generating anomaly scores for my train dataset (X) with a scikit-learn IsolationForest using decision_function
- Train a ConcreteML XGBRegressor (in clear so no FHE) with the training data and the generated anomaly scores (y)
Now i want to compare the prediction delta/difference between the IsolationForest scores and the ConcreteML XGBRegressor scores. While this works more or less fine for the Regressor from the original XGBoost library, I observe a constant right shift for the one from ConcreteML.
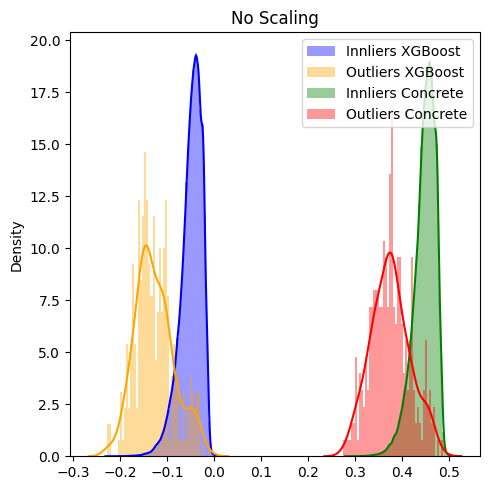
I made sure to use the same hyperparameters and checked that both Regressors are of the same XGBoost version (1.6.2). Since the anomaly scores from the IsolationForest are quite small (min=-0.25, max=0.3) i already tried to scale them which kinda solves the problem of the distribution shift.
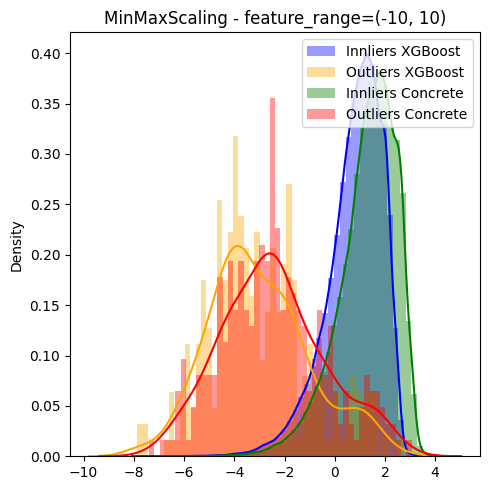
Anyway i would like to understand why this is needed and would be happy about any input ![]()