Thanks, your every answer is invaluable, as these pieces of knowledge can be hardly learned from elsewhere. It’ also amazing the you already know all of these flawlessly.
Regarding your explanation on division, you mean each bit is a standalone THFE ciphertext and we must build a logic circuit for binary division like this, right?
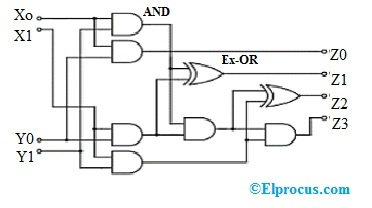
Is this also what Zama is doing, instead of doing division on a ciphertext as a whole number? Although other techniques like Ralph-Newton can divide a number as a whole, Zama is not using this because this is computationally inefficient?
==============
Regarding the 0 padding bit:
Case 1. if we do not use a negacyclic function, then our ciphertext’s MSB should remain to be zero, meaning that we should not rotate LUT V more than N-1 positions to the left. In this case, as we rotate V to the left by {0, 1, 2, … N-1} positions, the rotated V’s constant term coefficient will be {m_0, … m_1, … m_2, … m_{p/2 - 1} }. Here, we have repetitions between each m_{i} and m_{i+1} pair group, because we encounter for multiple noisy ciphertext states (m_i + e_{1,2,3,…} } that are mapped to the same plaintext m_i. And importantly, we should not rotate V(X) more than N-1 positions, because if we rotate V by {N, N+1, N+2, … 2N-1} positions, then the rotated V’s constant term coefficient will be {-m_0, … -m_1, … -m_2, … -m_{p/2 - 1} }, whose signs are flipped.
Case 2. On the other hand, if we use a negacyclic function, then the ciphertext’s MSB is okay to be 1. This means we are okay to rotate V(X) up to 2N positions to the left. So here I have a question. As we rotate V(X) to the left by {0, 1, … N-1} positions, the rotated V(X)'s constant term coefficients will be, like before, {m_0, … m_1, … m_{p/2 - 1} }. Then, as we continue to {N, N+1, … 2N-1} rotations, this time we will get {m_0, … m_1, … m_{p/2 - 1} }, whose negative signs are cancelled out by the negacyclic function. Note that although V(X) can have total 2N coefficient states, the latter N states are identical with the first N states (as the negacyclic function removed the negative signs). This is a problem, because now we never get the other half of plaintext states: {m_{p/2}, m_{p/2 + 1}, … m_{p-1} }. How do we get these states?
I am sorry for my continued question, but I really need to understand this correctly… I always appreciate you patient and considerate answers.