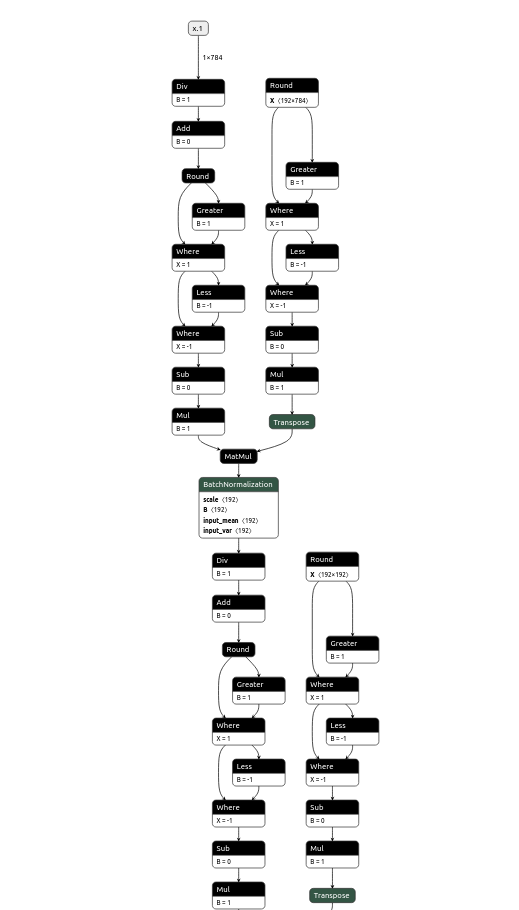
onnx look like this, and model.py are:
class MNISTQATModel(nn.Module):
def
init(self, a_bits, w_bits):
super(MNISTQATModel, self).
init()
self.a_bits = a_bits
self.w_bits = w_bits
self.cfg = [28 * 28, 192, 192, 192, 10]
self.quant_inp = qnn.QuantIdentity(
act_quant=CommonActQuant if a_bits is not None else None,
bit_width=a_bits,
return_quant_tensor=True,
)
self.fc1 = qnn.QuantLinear(
self.cfg[0],
self.cfg[1],
False,
weight_quant=CommonWeightQuant if w_bits is not None else None,
weight_bit_width=w_bits,
bias_quant=None,
)
self.bn1 = nn.BatchNorm1d(self.cfg[1], momentum=0.999)
self.q1 = QuantIdentity(
act_quant=CommonActQuant, bit_width=a_bits, return_quant_tensor=True
)
self.fc2 = qnn.QuantLinear(
self.cfg[1],
self.cfg[2],
False,
weight_quant=CommonWeightQuant if w_bits is not None else None,
weight_bit_width=w_bits,
bias_quant=None, # FheBiasQuant if w_bits is not None else None,
)
self.bn2 = nn.BatchNorm1d(self.cfg[1], momentum=0.999)
self.q2 = QuantIdentity(
act_quant=CommonActQuant, bit_width=a_bits, return_quant_tensor=True
)
self.fc3 = qnn.QuantLinear(
self.cfg[2],
self.cfg[3],
False,
weight_quant=CommonWeightQuant if w_bits is not None else None,
weight_bit_width=w_bits,
bias_quant=None,
)
self.bn3 = nn.BatchNorm1d(self.cfg[1], momentum=0.999)
self.q3 = QuantIdentity(
act_quant=CommonActQuant, bit_width=a_bits, return_quant_tensor=True
)
self.fc4 = qnn.QuantLinear(
self.cfg[3],
self.cfg[4],
False,
weight_quant=CommonWeightQuant if w_bits is not None else None,
weight_bit_width=w_bits,
)
when I open onnx, I find input and outout are all float, so I think the model is before quantized model. And I want export quantized model.