Quantization is a mandatory step to be able to execute the model in FHE so we will have to find the reason why the model does not train properly.
First I think it is worth checking to the input variables. (Affine) Quantization is naive in the sense that it will try to cover the full range of the input variable. It is important to check that the relevant range of the input data is well covered by quantization. Here is an example:
Imagine that one of the input variable has the following distribution:
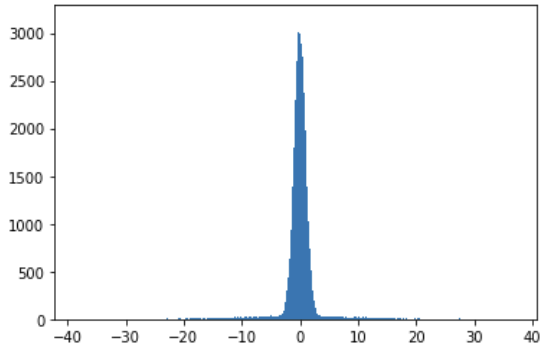
This kind of distribution is not ideal for quantization. If we use 6 bits to quantize this we will end up with the following:
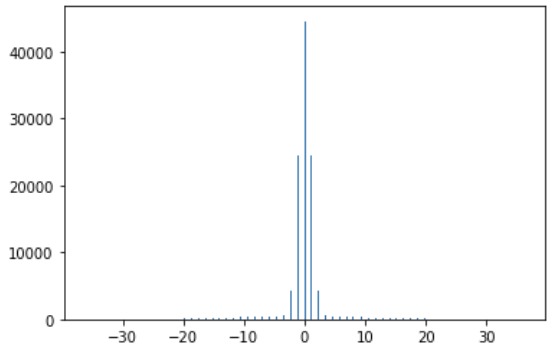
Over our available 64 quantized values, ~5 of them cover >99% of the distribution.
What could be interesting here is to train the model in floating point (fp32) without the extreme values to see if the accuracy is deteriorated by the change. You can do this using different techniques. One of them is simply clipping the values to a specific range e.g. -5, +5 in our example.
If the fp32 model is not too much impacted by this change then quantization is going to be much more effective over this specific feature.
If quantization seem to cover properly the input variables and the model to be trained is a linear model or a neural network then it is worth checking the distributions of the distributions of the model (weights and activations) since they are also being quantized. In this case, this discussion could be relevant.