Hi, I am currently estimating the latency of encrypted neural network inferencing, such as VGG or ResNet. I noticed that concrete-ml has these models in resnet and vgg. The timings of these CNN models are really promising, with 2h12min per inference of 7w7a quantized RestNet18 on a 196-core CPU.
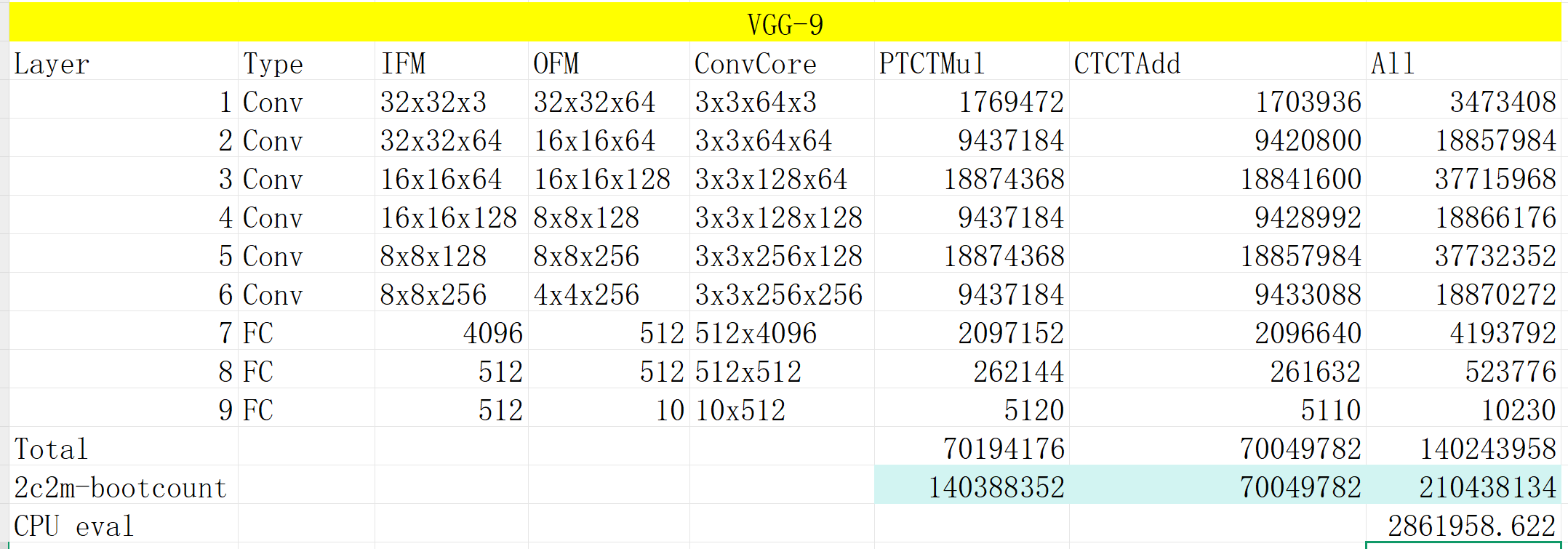
However, I failed to run the encrypted CNN inference on my own machine. So I tried to estimate the inference latency by counting the number of operations in the targeting CNN, VGG-9. Assuming the network is quantized with 4-bit weights and 4-bit inputs, the results would be:
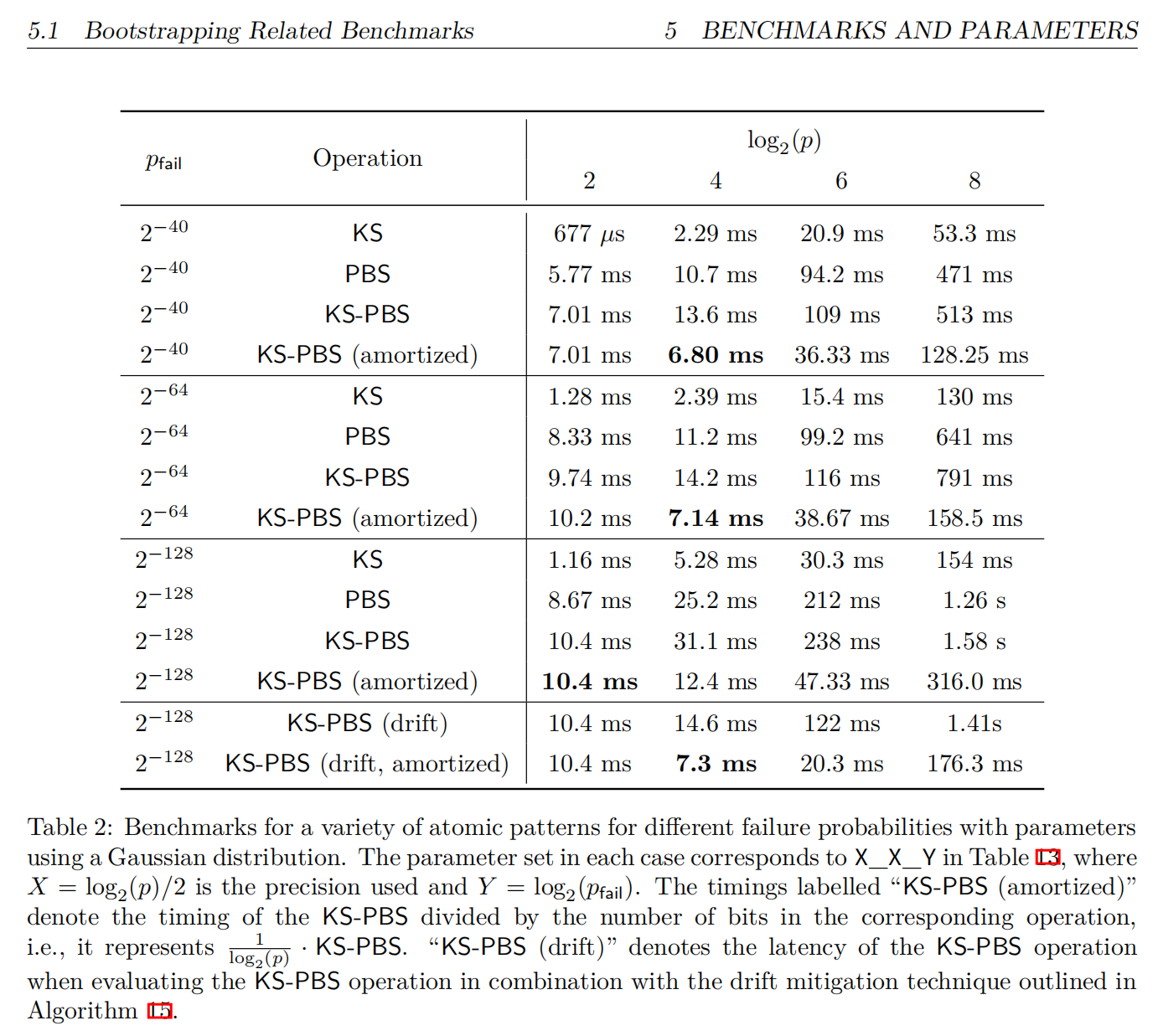
The thing that bothers me is that there seems to be a huge gap between the estimated latency and the reported one restnet. Notice that the ResNet is more time-consuming due to its deeper network structure. In the last two rows of my estimation table, the number of 2c2m PBS is calculated by PTCTMul*2 + CTCTAdd. Assuming each of PTCTMul is achieved by two 2c2m PBS. In summation of the partial products, the 8-bit accumulator is divided into 4 LWE ciphertexts and conducts PBS every 2^2 additions. Finally, the inference latency is estimated using PBScouts*13.6ms, which is the 2c2a latency reported by a Zama paper.
So, is there any suggestion to help me correct the estimation? I understand that Zama has done an enormous amount of work in improving the encrypted inference of CNN models. Techniques like QAT, pruning, and approximate ReLU have been developed to boost the inference speed. Multi-core CPUs have been used to parallelize the process. However, considering all that, there is still a gap between the estimation and the reported larency.
Furthermore, the estimation here is a simple calculation based on OPcounts of PTCTMul and CTCTAdd. There are functions like maxpooling and ReLU implemented in TLUs, according to TLU. What is the proportion of computing these TLUs in the total inference latency?
I read this post VGGinfer and the documentationdoc.
After considering the pruning that eliminates 50% of the neurons and the potential 192x performance boost from the 192-core machine used (Amazon EC2 Hpc7a), the total latency drops from 2,861,958s to 7,453s, still 186x slower than the 40s inference latency.
I think the main issue in your estimation is this assumption:
NumPBS = PTCTMul*2 + CTCTAdd.
Actually neither plain-text - ciphertext multiplication nor ct-ct addition not need any PBS. They are done purely levelled between LWE ciphertexts. This is achieved by finding cryptographic parameters for each layer of such accumulations (linear or conv layers), that allow these operations to be levelled. The parameters support noise growth that allows these computations to be exact.
The number of PBSs is given by the number of values in the output of these layers (e.g. number of output neurons of a linear or conv layer). PBSs are applied to these values. The precision of the PBS is given by the “rounding” term in the code. It is 7b for ResNet.
Just to complete what @andrei-stoian-zama said, you can use python run_resnet18_fhe.py --export_statistics and check the actual number of PBS in the resnet model (which is 6172672).
Also 13.6ms is not the timing of 7 bits PBS which we would have in the resnet. It’s rather around 300ms.
Thank you for your kind response. If the circuit runs in leveled mode, there should be less PBS indeed.
But I still have a question in terms of selecting the parameter set. In the above calculation, I chose the 2c2m message encoding as it has the best amortized computational complexity among all message encoding methods, according to the tfhe-rs-handbook by Zama. See:
Consider a circuit of accumulation M n-bit partial products. Leveraging a message encoding with i carry bits and j message bits, the n-bit input is divided into n/i LWE ciphertexts. During the accumulation process, PBS operations are conducted every 2^j additions. The total computation complexity of the accumulation circuit would be n/i times (2*M/2^j)-1.
As you have mentioned, if we select the param set that 2^j = M, there would be no PBS during the accumulation. But the PBS latency skyrocketed with the message bits i+j. Considering the increasing PBS latency and the amortization effect, the optimal parameter set would be the 2c2m encoding.
Take the pfail = 2^-40 KS-PBS case in the above table, the total complexity of the accumulation circuit with M=1024 and n=8 would be:
log_2 p --------- Latency_Estimation
2----------------------57,370ms
4----------------------27,798ms
6----------------------83,385ms
8----------------------130,302ms
Still, I am trying to understand the parameter choice with a bigger carry/message bits. I also tried to run resnet28 with the --export_statistics flag, as @jfrery suggested. It seems that the parameter set 2c2m is rarely seen in the PBS param.
So, is there any explanation for the mismatch? Thank you for helping me figure this out.
Concrete ML works somewhat differently than tfhe-rs:
Concrete ML encodes one activation as one LWE, while tfhe-rs needs radix-encoding (multiple LWE) per value (when the value is >2b).
parameter sets in Concrete ML are chosen during a compilation stage of the ML model.
in Concrete ML the p-fail can be configured as well, and is by default ~2^-40 but it can be reduced by the user when the model is robust to errors in the activation function.
We have experimentally shown that p-fail up to 0.01 or even more does not impact accuracy of the ResNet / VGG models. The amortized PBS latency (e.g. time for a big batch of PBS / number of PBS) on the GPU can be quite low on GPU (V100) or on big 192-core machines.
The examples in Concrete ML apply PBS only to the (6-8) MSBs of the accumulator (18-24 bit) of a conv or fully connected layer. Furthermore, the p-fail adjustment can keep the PBS complexity low. Thus, using 7b PBS is much faster than using 2c2m radix-encoded activations which require PBS for accumulation. Concrete ML accumulates LWEs (activations) of ~7-8b to produce 18-24 bit accumulated LWEs to which the MSB PBS is applied.
I kind of grasped the key idea here. By using the approximate PBS that only requires the MSBs to be exact, we can have an accumulator with a bitwidth of up to 24 bits while keeping the latency of PBS at a reasonable level.